AI音源分离
简介¶
AI音源分离是一种利用人工智能技术,尤其是深度学习和机器学习算法,从混合音频信号中分离出单独的声音源的过程。这种技术可以应用于多种场景,如音乐制作、后期音频处理、语音识别等。
行业方案¶
音乐人声分离是一项挑战性的任务,涉及到信号处理、机器学习和人工智能等领域。以下是一些行业方案和技术,用于实现音乐人声分离:
-
深度学习模型:深度学习在音乐人声分离中取得了显著的进展。使用卷积神经网络(CNN)或循环神经网络(RNN)等深度学习模型,可以训练模型来准确地分离音乐中的人声和伴奏。
-
时频分析:音乐信号通常以时频域表示,因此时频分析是音乐人声分离的重要技术。短时傅立叶变换(STFT)和小波变换等技术可用于将音频信号转换为时频表示,以便更好地理解信号的特征。
-
盲源分离:盲源分离是一种无需先验知识的信号分离方法,适用于音乐人声分离。独立成分分析(ICA)、非负矩阵分解(NMF)等技术可以用于盲源分离。
-
音频处理软件:有许多音频处理软件和工具可以用于音乐人声分离,例如Spleeter、Audacity、Adobe Audition等。这些工具提供了方便的界面和功能,可以帮助音乐人声分离的实现。
-
实时音频处理:对于需要实时音乐人声分离的应用,可以使用实时音频处理技术和硬件设备,如数字信号处理器(DSP)或专用音频处理器,来实现低延迟的音乐人声分离。
-
音频特征提取:提取音频信号的特征对于音乐人声分离至关重要。频谱特征、时域特征、声学特征等可以帮助区分人声和伴奏。
-
数据集和标注:建立大规模的音频数据集,并对音频进行人声和伴奏的标注,有助于训练模型和评估算法的性能。
AI分离算法示例图¶
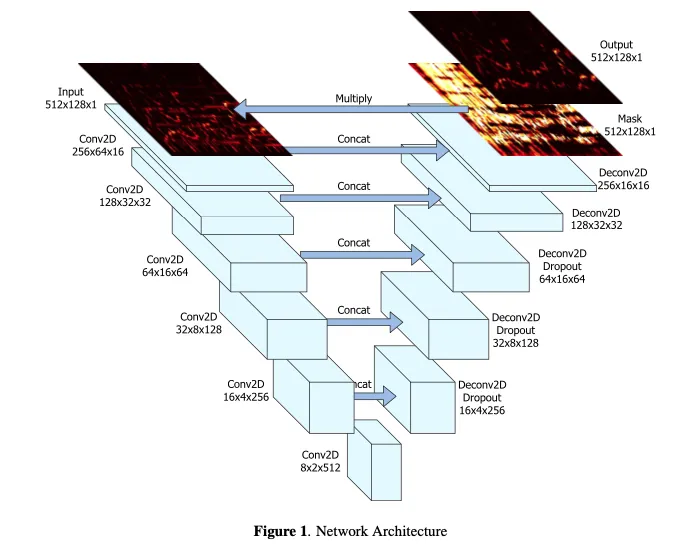
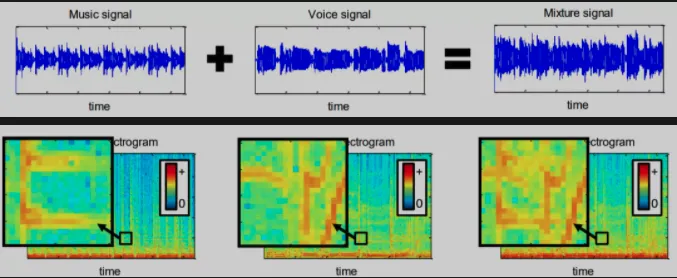
时频分离算法示例图¶
行业竞品¶
-
Spleeter:Spleeter是由Deezer开发的开源音乐人声分离工具,基于深度学习模型实现音乐中的人声和伴奏的分离。它提供了预训练的模型,用户可以方便地使用该工具进行音乐人声分离。
-
PhonicMind:P honicMind是一家提供在线音乐人声分离服务的公司,用户可以上传音乐文件并使用他们的算法来分离人声和伴奏。他们提供高质量的音乐人声分离结果,适用于音乐制作和混音。
-
Audionamix:Audionamix是一家专注于音频处理和音乐分离技术的公司,他们提供了专业的音乐人声分离软件和服务,用于音乐制作、后期制作和版权管理等领域。
-
iZotope RX:iZotope RX是一款专业的音频修复和编辑软件,其中包含了音乐人声分离功能。它提供了高级的音频处理工具和算法,用于分离音乐中的人声和伴奏。
-
XTRAX STEMS:XTRAX STEMS是一款音乐人声分离软件,由Audionamix开发。它具有直观的用户界面和高效的分离算法,可用于快速分离音乐中的人声、伴奏和其他音轨。
环境要求¶
-
计算资源:音乐人声分离算法通常需要大量的计算资源,特别是在使用深度学习模型时。因此,需要具有足够的CPU或GPU资源来运行算法,并且可能需要较长的训练时间。
-
内存需求:音乐人声分离算法可能需要大量的内存来处理音频信号和模型参数。因此,需要足够的内存来存储音频数据、特征表示和模型参数。
-
软件依赖:音乐人声分离算法可能依赖于各种软件库和工具,如深度学习框架(如TensorFlow、PyTorch)、音频处理库(如Librosa、FFmpeg)等。确保安装和配置了所需的软件依赖项是很重要的。
-
数据集:对于训练和评估音乐人声分离算法,通常需要大量的音频数据集。确保您有适当的数据集用于训练和测试算法。
-
模型预训练:如果使用预训练的模型进行音乐人声分离,则需要下载和加载适当的模型权重。确保您可以访问所需的模型权重文件。
-
输入输出格式:音乐人声分离算法通常要求音频数据以特定的格式输入,可能需要进行预处理或后处理。确保您了解算法的输入输出格式要求,并将音频数据转换为适当的格式。
-
性能要求:一些音乐人声分离算法可能需要较高的性能和低延迟,特别是对于实时音频处理应用。确保您的系统具有足够的性能来满足算法的性能要求
使用场景¶
- 音乐制作:音乐制作人可以使用这些工具来提取或分离音轨,进行混音或创作新的音乐作品。
- 视频编辑:在视频制作中,人声和背景音乐的分离可以帮助编辑者替换背景音乐或清除不需要的音频元素。
- 卡拉OK和音乐教育:提取清唱音轨可以用于制作卡拉OK伴奏,也有助于音乐教育中的扒谱和学习。
- 社交媒体内容创作:内容创作者可以利用这些工具为他们的社交媒体视频制作独特的背景音乐或清除原有的音频。
- 三维声对象内容提取:用于提取片源中的对象发声片源,用于后期三维声片源制作
算法调用¶
-
音乐人声分离:输入一段音乐,输出音频中自带的人声、背景声、鼓声、贝斯等音源信息
-
人声增强:输入一段带有噪声的人声音频,输出干净的人声音频(无环境噪声)
-
文本引导的音频信息分离:输入任意一段音频,给予文本信息,根据文本信息输出对应的音频内容
算法demo展示¶
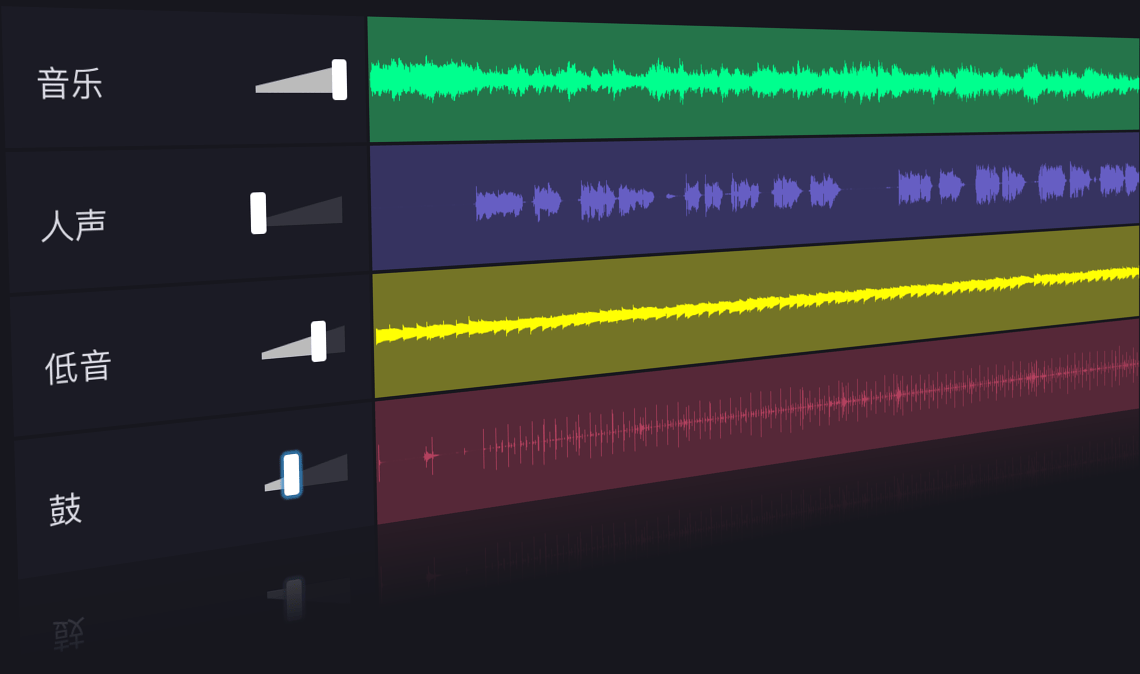
- 音乐人声分离
输入音频
输出音频
- 人声
- 背景声
- 打鼓声
- 贝斯
- 人声增强
输入音频
输出音频
- 人声
- 背景声
- 文本引导的音频信息分离
输入音频
输入文本信息
"accordion"
输出音频