音频美声
简介¶
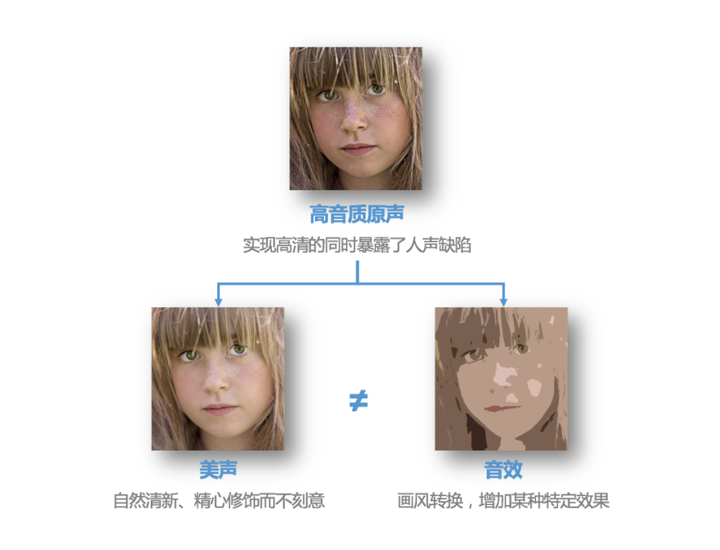
音效指的是通过调节EQ、混响,以及添加效果器等,给人声增加某种特定风格的效果,比如我们在合唱场景中看到的KTV、演唱会、录音棚、流行、R&B、留声机等效果。如果处理之后的声音,有空间感,或者不像你的声音了,那基本上就是经过了音效处理。
美声则不仅仅是简单地调节 EQ 和混响,而是把声学、语言学、心理学结合起来调节人声的音调、音色、动态、韵律、空间效果等,实现对人声的整体美化。它是在不改变人声的基础上,对人声进行调节。就像是对人像增加磨皮、红润效果,你并不会去改脸型、大眼。如果改变脸型,在音频中,就相当于变声了。所以经过美声之后,还能听出是你的声音,只是变得更好听了,比如更有磁性和活力。
`
行业方案¶
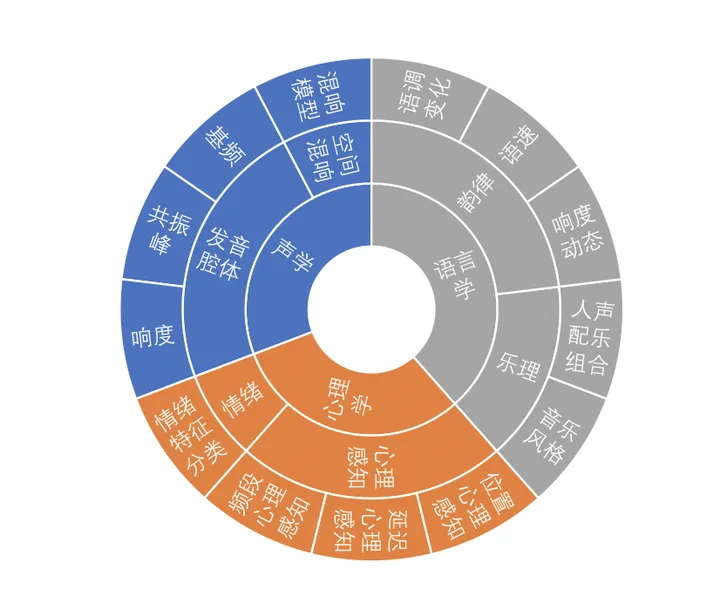
对于一般人来讲,“好声音”是一种“难以言喻的感觉”。有的声音很阳光,有的声音温柔甜美,你就是觉得它们声音好听。其实,我们会认为一个声音好听,主要受到声学、语言学、心理学三方面的影响。所以我们可以从语音声波产生的声学原理、空间声波传输的空间混响模型、与心理感知和情绪相关的心理学感知模型、韵律、人群差异的语言学等多个角度出发,对什么是好声音、好声音的数学描述特征指标进行多维分析,总结出不同种类好声音的一般规律。
如何把“好声音”数据化?¶
答案是:大数据与 AI 算法。事实上,我们也是基于大数据分析出“男性磁性声音”和“女性温柔的声音”有哪些特征的。
首先,我们已经知道了辨别“好声音”的理论基础:三个维度的多个因素让我们产生了“这个声音好听”的感觉。那么我们可以基于不同场景,如语聊、歌唱等,从性别、年龄、音色的维度确定一些“好声音”目标。
针对场景与性别设计算法¶
在设计美声相关算法的时候,我们还需要考虑应用场景。我们将场景主要分为两种:一种是语聊场景,比如聊天房、在线教学等。另一种歌唱场景,比如互动直播、线上 K 歌。
在歌唱场景中,绝大部分情况都会带有伴奏、背景音乐,背景音可以起到部分掩盖人声瑕疵的作用。而在语聊场景下,基本上是纯人声,没有音乐,所以人声的瑕疵不会受到音乐遮掩。我们需要对两种场景的算法设计,以及背景音的融合等方面,做差异化处理。除了场景,还要考虑另一个维度,那就是性别。男声和女声的主要区别是音调的高低不同。男性声带较长、较宽、较厚,所以振动时频率低,发出的音调也低,女性声带较短、较薄、较窄,所以振动时频率高,发出的音调也高。生理条件的先天差别,决定了男女声的发声比例的不同。从审美角度来讲,一般没有人希望男声温婉如玉,女声声如洪钟,所以生理和先入为主的审美决定了男女美声调校方向需要进行差异化处理。语聊场景下,人声瑕疵无遮掩,因此一般单纯的语聊美声处理不用考虑背景融合度、添加混响等问题,着重追求人声的可懂度和耐听度。在歌唱场景中,绝大部分情况都会带有伴奏、背景音乐,背景音可以起到部分掩盖人声瑕疵的作用,而语聊场景基本上是纯人声,瑕疵无遮掩,这样会对算法处理和背景融合等方面提出差异化的需求。
`
使用场景¶
音通话、互动直播、语聊房、开黑聊天室、K歌房、线上KTV、FM 电台、桌游狼人杀等语聊场景,以及互动直播、K歌房、线上KTV、FM 电台等歌唱场景
算法调用¶
暂无
算法demo展示¶
暂无